A few days ago, I was discussing the significance of monolithic architecture, microservices and service mesh. However, upon further thought, I realized it’s more relevant to consider when we should embark on the journey of transitioning to microservices and service mesh. In this blog post, I’ll delve into a fairy tale about service mesh and narrate the story of an e-commerce company that made the switch from a monolithic service to microservices and, eventually, ventured into the realm of service mesh. I’ll explain why and when this transformation was crucial and how they reaped the benefits of using it.
⚡ TL;DR
A service mesh is a dedicated infrastructure layer that handles service-to-service communication in modern, cloud native applications. It provides a variety of benefits, including:
- Reliability: The service mesh ensures that requests are delivered to the correct service, even when services are scaled up or down or restarted.
- Observability: The service mesh provides visibility into service-to-service communication, making it easier to troubleshoot problems.
- Security: The service mesh can be used to implement security features such as encryption and authentication.
This article is specifically created for engineers who want to learn modern software architecture and design patterns. If you’re an Architect, Backend Developer, or SysAdmin considering a shift from legacy systems to modern software services, this article could be of great interest to you.
Once Upon a Time in Monolithic Service: The Story of an E-commerce Giant
In the not-so-distant past, an e-commerce company made the journey to create a monolithic service for marketing their exclusive line of shoes and shirts. Their architecture featured a LAMP-Stack, with a Linux-based virtual machine (VM) hosting an Apache web server that served as the load balancer. MySQL served as the database and PHP was used for the application. This configuration proved to be remarkably successful, resulting in steady growth for the company. As a result, the company expanded its workforce and introduced numerous new features.
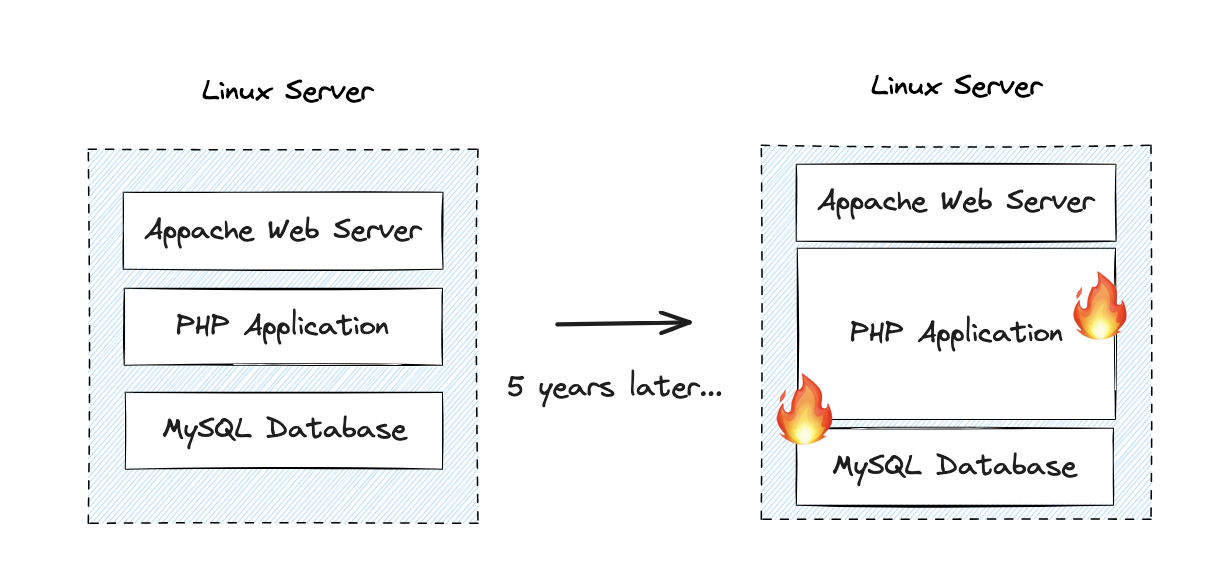
However, as the company expanded and their service became more complex, they faced a significant challenge. The system grappled with frequent downtime and production issues, with failures occurring all too often. Moreover, with numerous departments and extensive internal communication, scheduling a deployment date for all features became a daunting task. Code complexity began to resemble spaghetti code, and scalability was hindered because they had a single application, making it impossible to scale individual services.
Additionally, as the application grew in size, build and testing processes became time-consuming, discouraging developers from deploying small changes. Consequently, they opted for deploying all changes simultaneously, which led to failures due to the magnitude of the changes. In the context of error analysis, the system grappled with recurrent downtime, performance bottlenecks and production issues, frequently featuring obscure error points that necessitated lengthy root cause analysis, bug fixing, primarily due to inconsistent logging and monitoring. The absence of tracing also resulted in response time and CPU utilization issues. With limited visibility into the performance of individual services and the overall system, it became challenging to identify and optimize resource-intensive operations.
A curious engineer went to a tech conference, where they gained insights into microservice architecture and discovered that microservices can address all the problems they’ve been facing. Now, they got excited about switching from a monolithic system to microservices.
Step 1: From On-Premises to the Cloud
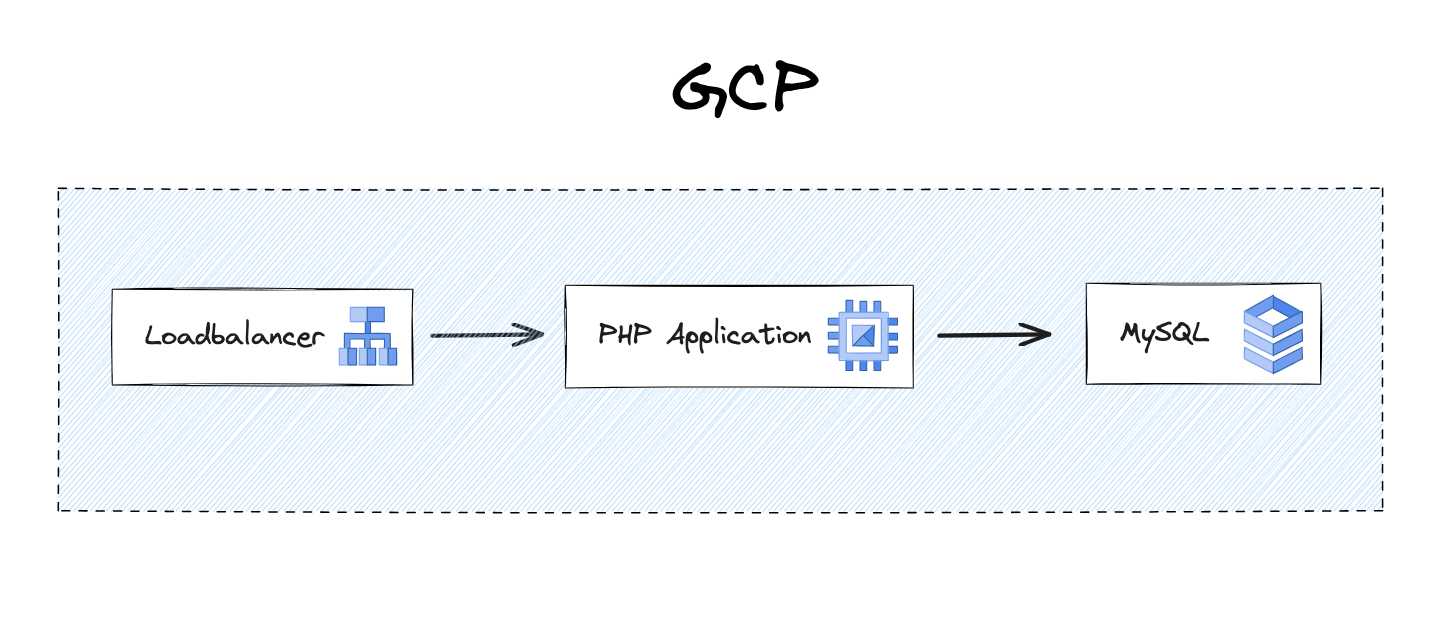
Initially, they migrated their on-premises commerce service to the cloud and divided the single component into their load balancer, application, and database components. This restructuring gave them more granular insights into individual components. Throughout the cloud migration, they leveraged cloud monitoring and logging tools to track basic component metrics as default to ensure better observability. As a result, they could independently deploy each of the three infrastructure components, enhancing resource planning and allocation.
Step 2: From Monolith Service to Microservices
Nevertheless, the situation remained far from optimal due to the existence of a monolithic application that encompassed all the features. The process of building and testing the application stretched beyond 2 hours before deployment, and it lacked the requisite flexibility for efficient service management and feature development. In response, the team planned to introduce new components, such as a data processing feature using Golang and a Frontend service with Astro. To improve the load time and interactivity of their website, they selected Golang for its lightweight goroutines and powerful concurrency model, and Astro for its ability to replace unused JavaScript with lightweight HTML. This led them to plan to deconstruct their PHP service and establish smaller, more agile, and flexible services.
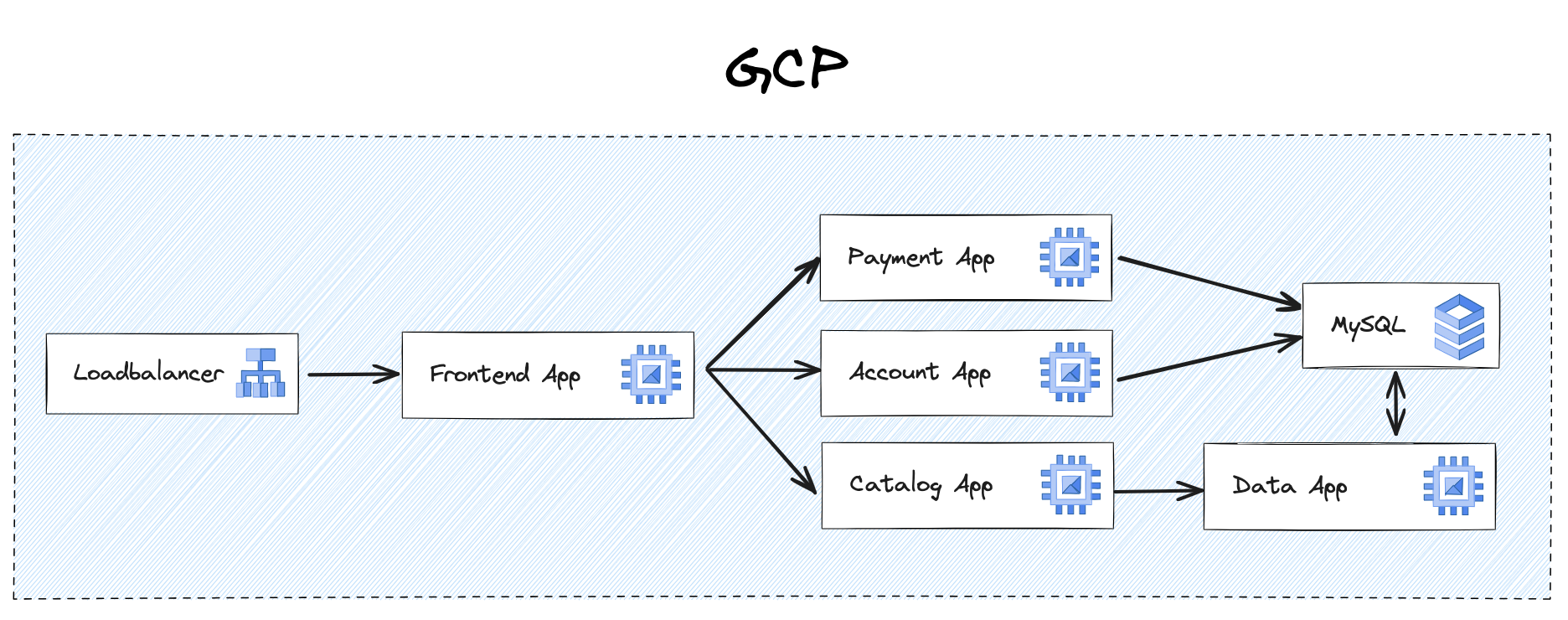
After a few months, though, the migration scalability became a breeze, and detecting and handling errors for quick bug fixes was significantly enhanced. Is this a happily-ever-after scenario? Regrettably, not quite.
Several years into the development of their system, they encountered a substantial challenge. The proliferation of numerous micro apps made it challenging to discern their interrelations. The complexity of API communication within the microservices architecture further complicated matters, and conducting integration tests became a daunting task due to interdependencies among services.
Another issue that arose was the need to maintain compatibility among services. If a service underwent major changes without coordination with other teams, it could potentially lead to downtime, as one service might not be able to communicate with another as it did before the change, impacting reliability.
Step 3: Upgrade Microservices with Service Mesh
Utilizing microservices requires being prepared to implement defensive programming to prevent potential failures, crashes, or unexpected behavior, especially in the face of network-related issues. Murphy’s law reminds us that it’s important to design systems to be robust to unexpected failures, but it also acknowledges that there are limits to what we can do to prevent all problems.
It’s imperative to prepare for a range of potential scenarios, including the following failure types:
- Temporary latency issues
- Downtime of other microservices
- Non-functional API components
Enhance network resilience with the following actions:
-
Configure the maximum allowable time using request timeouts that a system or application will wait for a response to a request
-
Manage the number of requests or operations using throttling that can be made within a specified time frame
-
Enable retry mechanisms for temporary call failures using exponential backoff
-
Prevent errors from spreading and provide time for service recovery using circuit breaker to ensure smooth system operation in the presence of network or service issues
-
Find and locate other services using service discovery to communicate and collaborate with each other without hard-coding their addresses or dependencies
Mastering Network Reliability with Service Mesh
Through the service mesh implementation, the team unlocked a range of powerful features. Service mesh gave them more network control, enabling them to manage network protocols (i.e. TCP, HTTP, and gRPC) and traffic (i.e. A/B-Testing) efficiently, and fine-tune deployments (i.e. canary-release) to optimize performance.
The team further enhanced security through service-to-service authorization, which effectively managed authorization solutions within the application, handling both internal and external access control requests. Additionally, they ensured encryption of communications by implementing mTLS.
Boosting Observability with Service Mesh
The team gained substantial benefits from their observability improvement too. With a service mesh in place, they were able to
-
collect access log and metrics for a complete view of system, network, and API performance
-
integrate easily with monitoring tools like Grafana and Prometheus
-
seamlessly integrate various tracing backends (like Jaeger, OpenTelemetry, and Zipkin) for flexible observability tailored to specific requirements
How does Service Mesh work?
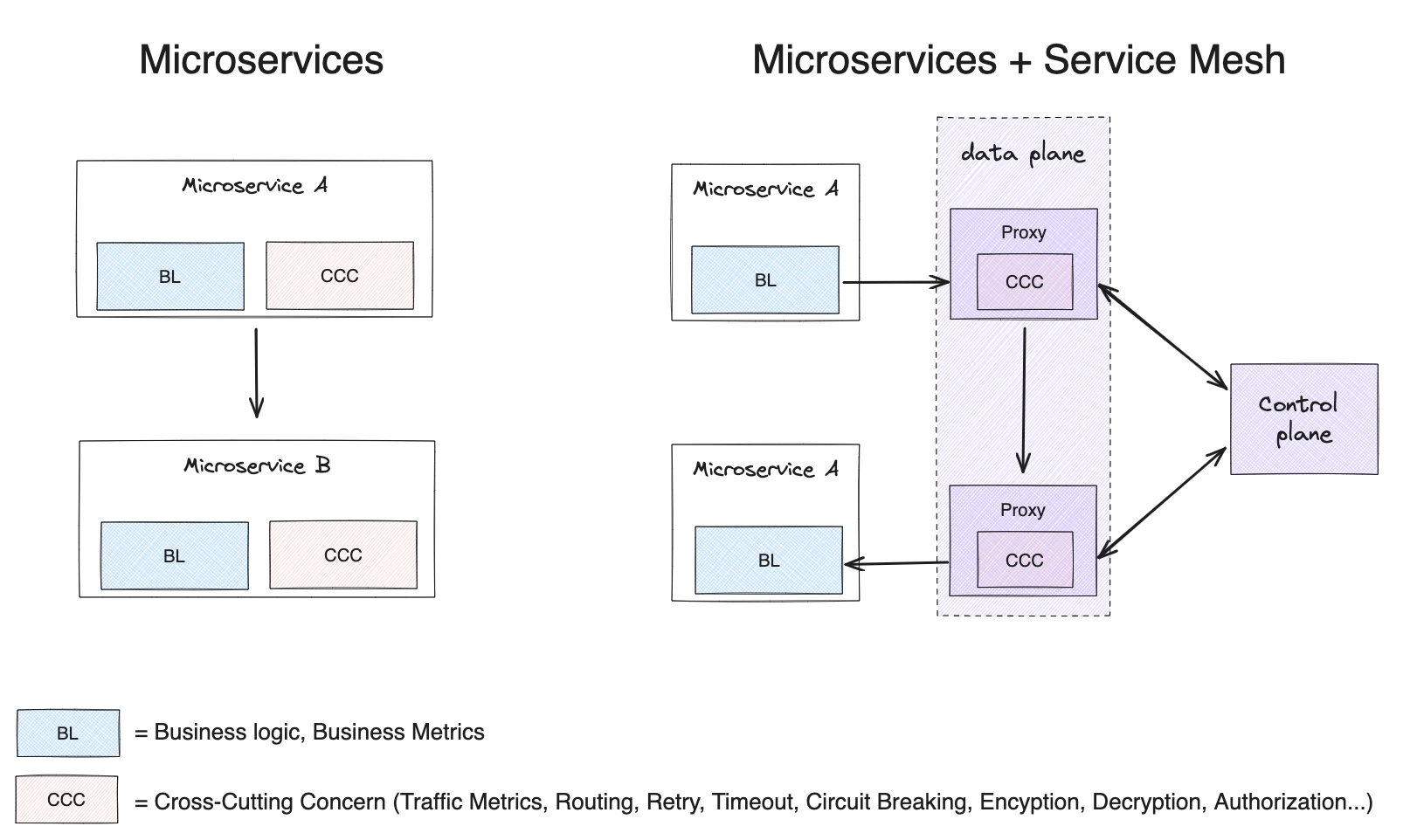
In a service mesh architecture, three distinct components come into play:
Control Plane
The control plane is the brain of the service mesh. It configures the proxies, manages security certificates, and sets the rules for how traffic should flow. It also collects data from the data plane and uses it to monitor the performance and health of the service mesh.
Data Plane
The data plane is the muscle of the service mesh. It consists of lightweight proxies that are deployed alongside each application. The proxies intercept all traffic to and from the applications and enforce the rules set by the control plane.
Sidecar Proxy
A sidecar proxy is a specific component within the data plane of a service mesh that is deployed alongside a business application. It is responsible for intercepting and handling all traffic to and from the application. Sidecar proxies are typically used to enforce security policies, collect metrics, and manage load balancing.
Conclusion
At times, you may opt for a monolith service, while other times, microservices or manually managed proxy sidecar containers could be the choice. Alternatively, you might embrace full automation through service mesh tools. The answer to which approach is best always remains the same: “It depends!” It depends on factors such as team size, expertise, resources, budget, business growth, and more. While not all companies are akin to MAMAA (Meta, Apple, Microsoft, Amazon, Alphabet) and may not require Microservices or Service Mesh, it remains essential to thoroughly evaluate your business’s growth prospects and anticipate potential challenges before taking the plunge.
If scalability isn’t a top priority and your team is small, starting with Microservices might not be the best idea. Instead, consider beginning with a modular monolithic approach, which can later be smoothly integrated into Microservices. It’s important to see Microservices as a long-term goal, adapting your architecture as needed. Here’s an interesting perspective on Modular Monolith: link
I hope this blog post has shed light on the challenges of building scalable software services and adopting a service mesh approach. In my next blog post, we’ll dive deeper into Istio architecture, core features, and design goals, and discuss how to choose a service mesh provider.